Today we first looked at several examples of Jeffreys priors. First, known variance but unknown mean; Second, known mean but unknown variance. The first was flat, the second was the usual 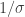
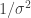
I pointed out that none of these is perfect. There may be no underlying group structure, so those priors may not be useful for some problems. The maximum entropy priors are not invariant under coordinate transformations, meaning that if you work a problem out in one set of coordinates, you may get a result that it incompatible with the working out of the problem in a different set of coordinates. And, since the Jeffreys prior is constructed from the likelihood as a sampling distribution (but the data are integrated out), some think that it is incompatible with the Likelihood Principle.
There are other ideas for constructing priors of this sort.
I again noted that if you have actual prior information, you should use it, and illustrated it with an example from astronomy.
We then turned to hierarchical Bayes models. Here the idea is that we may introduce new parameters that are not in the likelihood via a prior that is conditioned on the new parameters. We looked at an example involving baseball batting averages (trying to predict the end-of-season batting averages based on the results of the first 45 at-bats. I pointed out that because of sampling error, the averages at the extremes might be more extreme than they really should be, so that the player with the best batting average after 45 tries might just have been lucky, whereas the one with the worst batting average might have just been unlucky. There are differences in the ability of players, to be sure, but the first few at-bats are also affected by sampling error. So we modeled the individual players as a binomial with a probability that is unique to the player, but assumed that the individual probabilities are drawn from a distribution that represents the varying abilities of all players (modeled as a beta distribution). I demonstrated a program that calculates this. We’ll take this up again on Tuesday.
I finished with a short discussion of admissibility in frequentist decision theory.

November 3, 2012 at 3:14 am |
Hey guys,
I think Mark asked during the class whether Hierarchical Models are Bayesian Networks. There is certainly an overlap. Here is a tutorial that I have referred to a few times in the past: http://research.microsoft.com/pubs/69588/tr-95-06.pdf
If anyone is interested in having a discussion with me about that, please feel free to approach me. Bayesian Networks are one of the cornerstones in research and I am personally interested in them.
Have a great weekend,
-Ahmed