Problem set #6 can be found here. It is due on March 5.
Archive for February, 2009
Problem set #6
February 27, 2009Stat 295 2/26/09
February 27, 2009Comment: Last time we said that the rejection rate is 1/c (for the smallest c). In the problem c=1 is optimal for n=y=5, but it’s not optimal for other data choices. Remarked again the optimal proposal distribution is the target distribution. For this problem y|p~bin(n,p) and 

For prior N(0,.25) and y=n=5, 
One more comment about SIR. It’s easier to say than “weighted resampling.”
Result: Sample from posterior allows us to examine sensitivity to our assumptions. For example, sensitivity to the prior. If I want to change the prior to another, we can use SIR sampling using as weights the ratio of priors.
Have sample 





Leaving data out: Same idea, but now use ratio of the two likelihoods for the weights.
Onward. Talked about how if dimension of 
Nicholas Metropolis invented a key idea in this regard, although it wasn’t developed in image processing until the 1980s, and only in the late 1980s was it directed to statistical inference, in a seminal paper by Gelfand and Smith. Note also another paper by these two authors.
Jeff remarked that the name “Gibbs sampling” is very strange. It came from sampling on a distribution invented (I think) by the Yale physicist J. Willard Gibbs, who had nothing to do with how this sampling scheme works (he flourished well before computers, having died in 1903).
Gibbs Sampling:
Outline:
- Gibbs sampling algorithm
- Discrete probability example
- Normal model example
- (Maybe) Hierarchical model
Gibbs Sampling Algorithm: Let 
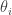
Suppose we know and can reasonably easily sample from the full conditional densities 

For example, 

- Let
be a vector of starting values.
- Sequentially generate
,
,
…
- Iterate step 2 to obtain a sequence of vectors
- Discard the first k iterations (burn-in) and use the remainder as a sample from
.


See this paper by Casella and George for a good introduction to the Gibbs sampling algorithm.
Specifying all the full conditionals gives a lot of information that allows us to overcome the curse of dimensionality. Note that replacing 


Example: Suppose 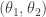




and the conditionals 

Note that we can compute the marginal distributions in terms of the conditionals (which we know) and the marginals of the other variable (which we don’t know…yet!) So, for example,

Also, 


Plug the second set of three equations into the first equation to get an expression for 





From these two we can get the remaining marginals 


We ran the Gibbs sampler for this in R. Did it for 1000 and 10000 samples, 10000 was better (closer to the exact value)
Stat 295 2/24/09
February 24, 2009I’m doing a lot of this from memory, because a glitch destroyed my first draft of the first half of today’s lecture. If I left out anything important, please post a comment!
Jeff started by recapping and motivating the rejection sampling technique. Recall that the idea is to have an enveloping density p(θ) that is easy to sample from and which has the property that there exists a constant c such that f(y|θ)g(θ)≤cp(θ) for all θ. Then, to generate a sample, we do the following:
1) Draw θ* from the density p(θ) and u~U(0,1)
2) Check if u≤f(y|θ*)g(θ*)/cp(θ*); if it is, set θ=θ* as the sample; if not, discard θ* and return to step 1.
3) Repeat 1-2 until a sufficiently large sample is obtained.
Jeff then tried to motivate the idea that we ought to choose a proposal that is as close in shape to f(y|θ)g(θ) as possible. (See picture below). Anyway, he asked us to consider the proposal distribution as θ~N(0,1), and let that be the prior as well, but with a data set consisting of 100 samples drawn from y~N(5,1) so that the likelihood is peaked sharply near 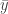

Here, the prior/proposal is the black curve and the likelihood is the red curve. We see that relatively few of the proposed points will lie near where the likelihood, and hence the probability of acceptance, is large. So a large proportion of proposed points will be rejected, and the sampling scheme will be relatively inefficient.
Jeff didn’t mention this, but suppose we had used as a proposal the actual posterior distribution. If this had been the case, then the ratio would have been constant! By picking c so that the ratio is 1 (i.e., choosing c=m(x)) then every single proposed θ* would be accepted! That is perfect sampling.
The next important concept we discussed is Importance Sampling. This is an effective way to calculate expectations. So, for example, we may want to compute E[h(θ|y)] for some function h(), where the expectation is taken over the posterior distribution of θ. So, our aim is to compute
![E[h(\theta)]=\frac{\int{h(\theta)f(x|\theta)g(\theta)d\theta}}{\int{f(x|\theta)g(\theta)d\theta}}](https://s0.wp.com/latex.php?latex=E%5Bh%28%5Ctheta%29%5D%3D%5Cfrac%7B%5Cint%7Bh%28%5Ctheta%29f%28x%7C%5Ctheta%29g%28%5Ctheta%29d%5Ctheta%7D%7D%7B%5Cint%7Bf%28x%7C%5Ctheta%29g%28%5Ctheta%29d%5Ctheta%7D%7D&bg=ffffff&fg=333333&s=1&c=20201002)
As before, we need a proposal distribution p(θ), but it doesn’t have to be an enveloping distribution (that is, no c need exist that causes the inequality to be satisfied for all θ). However, the support of p(θ) does have to contain the support of the posterior distribution.
The method exploits the fact that if h(θ) is any function, and p(θ) is the density of the random variable θ, then
![E[h(\theta)]=\int{h(\theta)p(\theta)d\theta}\approx\frac{1}{M}\sum_{j=1}^M{h(\theta_j)}](https://s0.wp.com/latex.php?latex=E%5Bh%28%5Ctheta%29%5D%3D%5Cint%7Bh%28%5Ctheta%29p%28%5Ctheta%29d%5Ctheta%7D%5Capprox%5Cfrac%7B1%7D%7BM%7D%5Csum_%7Bj%3D1%7D%5EM%7Bh%28%5Ctheta_j%29%7D&bg=ffffff&fg=333333&s=1&c=20201002)
where 
The procedure is as follows:
1) Generate a large sample {θj} from p(θ)
2) Compute
2) Compute

![E[h(\theta)] \approx \frac{\sum_{j=1}^M{h(\theta_j)w_j}} {\sum_{j=1}^M{w_j} }](https://s0.wp.com/latex.php?latex=E%5Bh%28%5Ctheta%29%5D+%5Capprox+%5Cfrac%7B%5Csum_%7Bj%3D1%7D%5EM%7Bh%28%5Ctheta_j%29w_j%7D%7D+%7B%5Csum_%7Bj%3D1%7D%5EM%7Bw_j%7D+%7D&bg=ffffff&fg=333333&s=1&c=20201002)
Jeff imagined using a uniform distribution for p(θ) (for this to work, the posterior must have compact support, and the uniform must include the support of the posterior but must not extend to infinity…we can’t sample from an infinite uniform!) The problem with doing this is that if the posterior distribution is highly peaked, then most of the samples will be taken where the posterior distribution is small, and in the sum above most of the weights wj will be small.
On the other hand, if we were able to sample from the actual posterior distribution, then all the weights would be the same, and all samples would contribute equally.
We then went over to SIR (Sampling Importance Resampling), which Jeff prefers to call Weighted Resampling. Whatever you call it, it can be an effective way to get an approximate sample from the posterior distribution. Why it is approximate will become evident in due course.
The idea is this:
1) Generate a large sample {θj} from a proposal distribution p(θ).
2) Compute weights at each sample point equal to f(y|θ)g(θ)/p(θ)
3) Divide each weight by the sum of all weights to get a probability at each sample point.
4) Generate the desired sample from the posterior distribution by sampling (with replacement) with probabilities equal to the probabilities computed at each point in step 3. This is done by sampling the vector of indices (1,2,…,N) that correspond to the j’s in the sample generated in step 1.
The w’s are the importance weights. Actually, if you use the R function ‘sample’, you can use the weights directly without bothering to normalize them as in step 3. But Jeff prefers to include step 3 for pedagogical reasons, and to emphasize the fact that we are sampling with a particular set of probabilities.
We noted that a SIR sample is not a sample from the actual posterior distribution (rejection sampling is), since it is actually a sample from the discrete distribution over the points in the original sample. However, if the number of points in the original sample is large, the result can be a very good approximation, and it will approach a sample from the actual posterior distribution as the number of points in the original sample →∞
Remarks:
1. SIR does not need a dominating constant c as in rejection sampling.
2. The resulting sample only approximates the posterior. The approximation improves with larger N and p(θ) is close to f(y|θ)g(θ)/m(x)
3. It’s essential to have enough points in initial sample to cover region of interest for f(y|θ)g(θ).
4. When the dimension of θ is large, it becomes impossible to find an adequate p(θ), and we must resort to MCMC methods.
5. When using R’s ‘sample’ function, it’s sufficient to write “prob=w”; you don’t actually have to divide by the sum of the w’s…but Jeff prefers, for pedagogical and other reasons, to do this extra step.
What happens if p(θ) doesn’t well approximate f(y|θ)g(θ)?
The weights are ratios. They will be small where proposal is big and the posterior is small. They will be large where proposal is small and weights are large; but there will be relatively few samples (because the proposal is small) there and the discrete approximation will be bad (points not dense there). We would need m to be huge for this to work.
On the other hand, if the proposal is a good approximation to the actual posterior, then the weights will be about equal and the sampling will be efficient over the set of sampled points.
Rejection and SIR don’t work well if the number of dimensions is large.
c=1 is the bounding constant for the homework problem. (You will need to prove this when you do the problem).
ALWAYS USE LOGS! The reason is that calculating the posterior instead of the log posterior will often result in machine underflows and/or overflows, where the number computed is either less than the smallest positive number that the machine can express, or larger than the largest that the machine can express, which can (silently, so that you do not know) introduce errors in the result. Thus, in Jeff’s calculation of the weights for SIR, he actually computes the log of the proposal and the product f(y|θ)g(θ), and subtracted the log of the maximum before exponentiating. This prevents these undesirable things from happening.
Comment Problem Set #4, problem 3
February 23, 2009The third problem in the fourth problem set (Albert, p. 73, #6) is somewhat ambiguously stated. In particular, it is not stated clearly what the second parameter in the definition of the prior is. Is it a rate, or a scale?
Most people took it to be a scale. I wrote Jim Albert, and learned that throughout the book, he’s using a rate. See Section 3.3, where he defined the gamma density. I did not take any points off if you did the calculation assuming that it is a scale=1/rate. But in the future, when you see a gamma distribution in Albert’s book, remember that the second parameter is a rate!
New Chart Set
February 23, 2009The seventh chart set, “Doing the Integrals,” is now available.
Using R to plot things
February 20, 2009This link was posted to Andrew Gelman’s blog today. There are a number of examples of plots made with R, and you can get the code that produced them.
Stat 295 2/19/09
February 19, 2009The assignment for 2/26 will be found here.
We had been talking about the Laplace approximation, and gave an example in terms of the beta-binomial problem. Jeff left out the subscript j so you need to go back to your notes and fix this.
yj|θj~bin(nj,θj)
θj~beta(α,β)
From this model we derived the marginal density for yj|α,β. We work with these marginal densities. We then reparameterized twice to get something that looked reasonable. Chose a prior (see notes last time), plotted the contours.
Can we get an approximation to this? Here’s where the Laplace approximation comes in.
p(θ|y) ∝ f(y|θ)g(θ)= exp(h(θ)) ≈ (expand h(θ) around θ0 as in the previous blog entry).
i.e., the posterior ≈ N(θ0,-(h”(θ0))-1)
We wrote the explicit form of the Hessian where θ is a p-vector. First write the first derivative (gradient) which is a vector. So the second derivative consists of partials of the first partials, which makes it a matrix (the Hessian). It is a p x p matrix. Explicitly, here it is:

In class, we noted that the Hessian is a symmetric matrix (assuming that the function h is not pathological). It was not noted, but should have been, that the matrix is negative definite, that is, if x is any (column) vector, then xTh”(θ)x≤0, with equality only if x=0. This is a consequence of the fact that the matrix is evaluated at the maximum of h. Just as the second derivative of a function of one variable is strictly less than zero at a maximum, the Hessian, analogously, is negative definite.
The R function ‘deriv’ will take analytical derivatives and give you R code to compute it.
LearnBayes has a function Laplace that computes the posterior mode and the Hessian and spits out the approximation. It uses an R function ‘optim’ that does the dirty work.
We talked about the Newton-Raphson method for finding a root. Need second derivatives to do this. Converges quadratically (when it converges…)
Albert has redefined the definition of his ‘laplace’ function. I will post the code when Jeff sends it to me. We ran the code and got the variance-covariance matrix. Note, always check that the N-R method converged. The Laplace approximation just uses this output to give a contour plot, using Albert’s function is ‘lbinorm’. Did not look much like the actual contour plot for the real function.
Note that if Laplace is a good approximation, then a 95% credible interval is given by going out 1.96 standard deviations in each direction.
Move on to rejection sampling. Our problem was not well-approximated by Laplace, so we don’t want to use it for inference. A better terminology would be “acceptance-rejection” sampling.
It is a clever way to generate an independent sample from the posterior.
Objective is to generate a random sample from the density g(θ|x)=f(x|θ)g(θ)/m(x) where m(x)=∫f(x|θ)g(θ)dθ
Algorithm: Let p(θ) be a density that we can easily sample from (e.g., a normal or a beta or a gamma) and such that there exists a constant c satisfying g(θ|x)≤cp(θ) for all θ.
p(θ) is called a proposal or enveloping function.
To obtain a sample from the posterior distribution, do the following:
1) generate θ* from the proposal distribution and u~U(0,1).
2) Check if u≤f(x|θ*)g(θ*)/cp(θ*). If it is, accept θ=θ* as a draw from g(θ|x). If not, return to step 1.
3. Repeat steps 1-2 to obtain a sample of the desired size.
Remarks:
1) Finding a suitable p(θ) is the difficult part. It must dominate the target distribution. Also, you want the proposal to approximate the target well, otherwise you will get many rejections and the program will run quite slowly.
2) It can be shown that the acceptance rate is m/c where m=∫f(x|θ)g(θ)dθ. Since the acceptance rate goes as 1/c, if the match is bad you may need to pick a large c and hence get a low acceptance rate.
3) An advantage is that we don’t have to worry about mixing or convergence.
4) Often a fat-tailed distribution like a t is a better choice than, say, a normal…you need to have the proposal dominate out in the tails. This is what we’ll do with the beta-binomial problem.
5) (Not mentioned in class): We don’t need to know the normalizing constant m(x) for this scheme to work!!!
Example: “betabinomial.r” which will appear on the web page. Uses a t with 4 dof as the proposal distribution, with same mean and scale matrix from the Laplace approximation.
We still need to find the bounding constant c.
Procedure to find c: Find d such that log[f(x|θ)g(θ)]-log(p(θ)≤d for all θ:. Then c=exp(d). This procedure is implemented in the LearnBayes function ‘betabinT’ with the function ‘laplace’.
We ran the code to get the appropriate bounding constant. Then we obtained a sample by rejection sampling. We showed that it looks like the contours, and computed means, showed the marginal distribution, quantiles, etc.
