We went through the first three bullets on the review sheet.
The first one, on the suspected cheaters, asks you to advise the professor. You can tell the professor what the likelihood is, but the professor is going to have to decide on a prior. He won’t be able to do this based on reports of the particular students, because of privacy laws. So he’s going to have to use his experience, perhaps his estimate on how common cheating is from other classes he has taught.
For the likelihood, we expect the students to answer correctly, so the 17 correct answers don’t give us any information. But the eight wrong answers do, since they were answered identically. If the distractors and the correct answers are equally plausible, the probability of one coincidence is 0.2, and that of eight coincidences is 0.28. However, it is very difficult to write good distractors, and it is likely that the real probability of one coincidence is somewhat higher, perhaps one chance in three. Whatever it is that you decide, call it p, and so the likelihood for no cheating is p8. Of course, if one student copied from the other, the likelihood for that state of nature is 1.
With prior (from the professor) and likelihood in hand, you are then able to tell the professor what the posterior probability of cheating is, and then he can take it from there as to what to do about it.
The second bullet is a problem we’ve discussed several times, so I’ll be brief. The important thing to clarify is whether the sampling of the taxis is with or without replacement. In the case of the taxi problem we discussed earlier, we know that it was with replacement, since we saw one of the taxis twice; but in this case, you can argue perhaps that the sampling was without replacement, since you saw these taxis on your way to the hotel and it’s unlikely that you’d see the same taxi twice.
If the sampling is with replacement, then the factor in the likelihood for taxi #N is 0 for n<N and 1/n for n≥N. There is one factor for each taxi, and because you saw taxi #150, the combined likelihood is 0 for n<150, and 1/n7 for n≥150. On the other hand, if the sampling is without replacement, the combined likelihood is 0 for n<150 and 1/(n(n-1)(n-2)…(n-6)) for n≥150. In practice, the answers you get will be fairly similar no matter what.
For a prior, the HINT says that it’s more likely that you got dropped into a small city with few taxis than into a large city with many taxis. So you want a prior that decreases with n. A very common prior to use in situations like this is a “power law” prior of the form 1/na, where a is a positive number, probably of order 1 or 2. Power laws describe all sorts of things, e.g., the number of stars of mass M, the number of people that have assets of $D dollars, etc. So this is a reasonable prior. You should not cut the prior off at 150 taxis, because that assumes you’ve looked at the data, and priors are supposed to be determined before looking at the data. Besides, the likelihood automatically takes care of that.
The third bullet is the test of the drug. This is a double-blind experimental design: Neither the doctor nor the patient knows if the pills the patient gets are placebo (or the old drug) and the new drug being tested. This is important, because even if a pill has no activity (it’s a sugar pill), there are psychological effects on the patient that cause even a placebo to have some effect, even if small.
The data are 25 of 50 patients cured in the “control” (placebo) group and 30 of 50 patients in the experimental group. The likelihood is shown in the whiteboard shot (for the special case r=0.25, s=0.35).

That number goes into the appropriate slot in a 100×100 grid, which could be a spreadsheet, for example, as shown by the arrow in the next chart for the likelihood:

Replacing the 0.25 and 0.35 with all ten of the points in our grid for r and for s yields the numbers we should put in the other 99 slots. That gives us the likelihood grid.
We’d need a similar grid of 100 numbers for the prior (you can imagine it lying underneath the likelihood grid for example). Multiplying corresponding grid points for the prior and the likelihood, we get a number for the joint that goes into a corresponding grid point. Add all 100 numbers up to get the marginal. Divide the marginal into each joint to get the corresponding posterior probability.
We are interested in the probability that the new drug is better than the old drug. Just add up the probabilities in the grid points where s>r, which means all of the entries in the upper right hand quadrant of the diagram, as shown in red below:

Finally, as we noted, the CEO of the drug company is going to have to decide whether to spend $100 million dollars to bring the drug to market. That $100 million is a toll gate that he has to go through if he decides to go further. Some of the things he’ll have to consider are: How big is the market, so that there will be enough patients to pay back the initial cost and yield a profit for the stockholders? How promising is the drug, really, as indicated by our preliminary study with 100 patients? If it isn’t much better than the old drug, which is quite cheap, it’s going to be hard to convince people to use the new drug (although various kinds of campaigns, TV for the patients and drug salesmen for the doctors) might change that. The company will have exclusive rights over the drug for only 17 years; is that going to be long enough to pay back our initial investment and earn a substantial profit? Etc., etc.
We’ll take up the remaining bullets on Friday.

 the states of nature, we start with a prior on
the states of nature, we start with a prior on 
 . Starting there, we generate a new
. Starting there, we generate a new  from a uniform distribution between
from a uniform distribution between 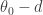 and
and 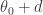 . We then compute the ratio of the joint distribution at the new point to that at the old point. We generate a uniform random number between 0 and 1, and compare it to the ratio. If it is less than the ratio, we jump to the new value, so
. We then compute the ratio of the joint distribution at the new point to that at the old point. We generate a uniform random number between 0 and 1, and compare it to the ratio. If it is less than the ratio, we jump to the new value, so  , otherwise we set
, otherwise we set  . We then repeat the procedure as long as we wish, obtaining a large sample.
. We then repeat the procedure as long as we wish, obtaining a large sample.
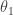 and then on
and then on 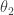 and then repeat.
and then repeat.


















