This article details some of the reasoning that was used by the recent panel recommendations regarding breast cancer screening that we’ve discussed in class. This is worthwhile reading.
Archive for November, 2009
New article on the breast cancer issue
November 23, 2009HCOL 195 11/20/09
November 20, 2009I’ve put the link to the NPR discussion I mentioned in class here and below.
And here is an interesting article from the New York Times that describes the history of breast cancer ideas, going back to the 19th century. Some of the debate today is very old.

Question 1
The distinguishing characteristic of Question 1 is that there are two independent cure rates; this means that the table of posterior probabilities must also be two-dimensional, that is, a square table. The posterior probability of each combination of cure rates r and s is the product of the posterior probability of r and that of s, and it is put into the appropriate square in the grid. Then the probability that the cure rates are equal is given by the sum along the main diagonal (red boxes in the picture), and the probability that B is better than A is the sum of all the numbers above the main diagonal, where s is greater than the corresponding r.
")
Question 2(A)
In the general picture, we see that according to the probabilities, the expected number of survivors is 200 in each case, but in the risky case, it’s possible that everyone will be killed. The risk-averse general would choose the sure thing rather than risk everyone being killed. What that really means is that the value of the 600 soldiers is less than three times the value of the 200 soldiers. That’s illustrated in red in the diagram, where we put 550 rather than 600 to reflect this assessment of this general.
")
Question 2(B)
In this problem, the objective is to win, and so there are just two gains, one for winning and the other for losing. To make the arithmetic come out nicely, 30 is a good gain for winning and 0 for losing. There are only two possible decisions, to go for the “sure thing” of 200 soldiers, versus the “risky” choice of possibly 600 soldiers, but possibly none. For the sure thing choice, the only chance node is the one that tells us whether we win or lose. But for the risky choice, the first thing that happens is that we take the soldiers to the scene of the upcoming battle, so that’s the first chance node. Once we get to the scene of the battle (if we do), then the battle takes place, so there is a second chance node for each of the two possible outcomes from the trip. We see that the expected gain is greater if we use the “sure thing” branch.

Question 3
Some background on this story can be found in the NPR story from All Things Considered, here, as I promised in class. This is a very interesting conversation, you can listen online, download an mp3 for your mp3 player, or read the transcript. I found the discussion very illuminating.
The New York Times today also had a very illuminating article about how the history of understanding cancer over the last 150+ years also influences the discussion today.
The diagram is very simple; you have the loss of one extra life ($5 M according to our class discussion) versus the cost of ten mammograms per person ($3M) plus whatever the loss is for the false positives (200, or 10% of the number in the group in the statement of the problem; but I found out that the actual number is closer to 1000). Also for simplicity I have drawn the diagram for 1 extra life saved out of 2000 women tested; the error is 5%, smaller than the error of other numbers that go into the calculation, so this is justified. We see that (in the diagram again) we will be indifferent if the additional cost C of the false positives is such that $5M=$3M + 200C. That makes C=$10,000. With the more accurate number of 1000 false positives, C=$2,000. Any C larger than that corresponds to a decision not to test.
Comments:
The actual discussion in the media indicates that they were not doing a cost-benefit analysis like the above, but rather trying to weigh the human cost of one extra life saved versus the human cost of false positives, which would include the anxiety, the pain of additional testing, the risk of additional testing (X-rays for example have a small association with cancers in and of themselves), the risk of unnecessary surgery that might cause a woman to be disfigured or even lose a breast, the risk of a woman dying due to unnecessary surgery. It’s not clear how they weighed the various costs.
Also, consider that money not spent for testing could be used for something else. Is the cost of testing in this age group the best way that we could spend the money? The amount of money available for health care is not unlimited, as Congress is finding out. It might be that more lives could be saved if the money were spent elsewhere.
Finally, as I mentioned in class, the 10% false positive rate is really for one mammogram. If you have ten mammograms in ten years, the probability is a lot closer to 50% that one of them will come up with a false positive. This explains the difference between the number I gave you in the question and the figure of 1000 false positives that the media is reporting. It also says that the probability of a false positive would be reduced if mammograms were only given every two years (five versus ten). This would reduce the negative outcomes from false positives. It would also cost less money, money that could be used in other, and possibly more productive ways. And (according to the discussions I’ve seen), the additional risk of a woman dying who could have been saved would be very small.

Question 4
This one is pretty straightforward and is similar to many that we’ve done during the course. The probability of observing 7 items of the first kind, 2 of the second, and 1 of the third, is 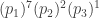

Question 5
This is similar to the problem we discussed on the study sheet, except that instead of H/T, there are three equally probable ways that the die can come up. So the probability of each of these ways is 1/3, and the calculation of the probability of hearing “yes”, given that p is the true proportion of people who did what the subject of the question is, is (p+1)/3=0.4. This gives p=0.2.
HCOL 195 11/16/09
November 17, 2009On Monday the first thing I did was to flesh out a bit the calculation of the probability of saying “yes” and “no” in the polling example. It’s a straightforward application of probability theory:

Details of calculation of probabilities for survey problem
We then talked about the problem of setting up an “expert system” that takes input (patients, doctor’s diagnoses; emails, receiver’s opinion that it is spam), and after “learning” through a large amount of examples, can then do the diagnoses or decide on whether a new email is spam or not. We did this by considering the spam problem. By having the program look for a large number of words in the email, together with the recipient’s opinion that the message is or is not spam, allows us to estimate the conditional probabilities that a particular word (e.g., Viagra, hello) is in the message, given that the message is or is not spam. We do this by simply tallying up the number of occurrences and dividing appropriately. We can also get estimates of the prior probability of spam/not spam simply from the proportion of spam messages to the total.
However, the formulas I put on the board weren’t correct. I should have written that the conditional probability of a word, given that it is spam, is given by the number of times a word appears in a spam message, divided by the total number N of spam messages (I’m not sure what I said). That’s just
P(word|spam)=N(word,spam)/N(spam)=P(word,spam)/P(spam).
Here I’m just using the fact that
P(word,spam)=N(word,spam)/N(messages)
and
P(spam)=N(spam)/N(messages)
so that the number of messages, N(messages) cancels out.

Getting statistics on spam tokens
We then used Bayes’ theorem to estimate the posterior probability of a message being spam, given that it contains words 

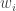
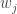

Calculation: Is It Spam?
I’ve commented on last Monday’s class
November 15, 2009I’ve commented on last Monday’s class here.
HCOL 195 11/13/09
November 14, 2009The first problem we discussed is the second half of the drug company’s decision.
Basic decisions are to continue research on marketing the drug, or to stop. Since the “sunk costs” of the research so far are the same regardless of what we do now, we can set the loss or gain at zero (remember, the gain/loss can always be added to by an arbitrary constant, or multiplied by an arbitrary scale). Also, since the goal is to make a gain, it’s probably best to frame this decision in terms of gain (utility) rather than loss. So, “do nothing” has a gain of zero.

Decision part of drug company problem
If we were to decide to continue the research, from the data we already have there is a probability p that the drug is better than the old one, and (1-p) that it is not. That is a probability node (we could use as our p some higher criterion, such as that the new drug is twice as good as the old one.) To test the new drug will cost $30 M (probably low, by the way). If we test it, there is a possibility that the early testing may not pan out. The probability of cure rate may end up at q, which might even be less than the p that we got in the early tests. That has to be folded into the costs of marketing, bringing the drug to market, and the possible rewards of pricing the drug so that the expected number of doses sold will (over the 20-year lifetime of the drug) handsomely reward our company and our stockholders. That is illustrated in the above chart in a very sketchy way.
Our next problem was to consider the claim of an astrologer that he has powers that allow him to predict the future with 85% acccuracy. He makes 11 predictions, 4 of which are correct. What is the probability, given that he has some powers, that he can predict the future with 85% accuracy? That leads to our usual spreadsheet (where the division into 0.05, 0.15, …., 0.95 is for illustration and is adequate for the exam):

Spreadsheet for astrologer problem
As usual, the likelihood is p4(1-p)7 where p takes on the values that we put into our spreadsheet. We complete the spreadsheet in the usual way, and then to decide the probability that the astrologer has proven his case, given that he has the powers he claims, we add the probabilities for the states of nature ≥ 0.85 (that is, for this spreadsheet, 0.85 and 0.95).
But that doesn’t take into account our own experience. When we discussed this in class, people seemed to be skeptical about whether some people could actually make such predictions. To focus things, I asked whether people would think that I had abilities to predict things if, you given a fair coin and tossing it yourself out of my view, I were to predict that it would come up heads or tails correctly, no one would be impressed. If I did it ten times in a row, (one chance in 1000), some would pay attention. And if I did it 100 times in a row, (one chance in 30 million) most would think that something (maybe some sort of cheating) was going on. So that leads to a short spreadsheet like the one below, which puts a very small prior probability on the hypothesis that the astrologer really has the claimed powers.

Astrology, considering our prior probability of the reality of such powers
We then considered the problem of polling people when there are controversial issues that some people might lie about when polled, as for their personal drug use, or their opinions on controversial subjects. Polls can be skewed when people lie.
So, for example, the poll is constructed so that the person being polled tosses a coin. If the coin comes up “heads”, then he is instructed to answer one way always (i.e., “yes, I used drugs last week.”) If it comes up “tails”, then he is instructed to tell the truth. The idea here is the the pollster has no idea whether the person being polled used drugs or not, so that protects the privacy of that person. But nonetheless, the pollster can back out the desired information about the group. Here’s what I wrote on the board:

Polling technique
The point is this: We need to know the probability that a person will say “yes,” given any probability p that the person has used drugs (or whatever the question is). That’s not hard to figure out.
P(“yes”|p)=P(“yes”,H|p)+P(“yes”,T|p)
=P(“yes”|H, p)P(H|p) + P(“yes”|T,p)P(T|p)
=1*(1/2)+p*(1/2)
=(1+p)/2
I didn’t do the calculation this carefully, but this is the result. For the probability of “something happens,” the probability of “says no”|p is (1-p)/2.
So, if 57% of the respondents answered “yes,” then the naive calculation is that
(1+p)/2=0.57, or p=0.14, the proportion of respondents that used drugs (or whatever the question is).
But we can do better. The quantities we’ve computed above are the likelihood function, and we can put them into a spreadsheeet:
 Spreadsheet for controversial poll
Spreadsheet for controversial poll
The spreadsheet can have 10, 100, 1000, however many rows we need. The more we take, the more accurate the calculation. Or, we could, if we knew about calculus, do a fancy calculation that uses that skill. (This would not lead to better insight into this problem, only to greater accuracy.)
HCOL 195 11/11/09
November 11, 2009The first problem was the test cheating problem. You are to advise a professor who had two students, one of whom sat behind the other, who answered a 25 question multiple-choice test with identical answers, 8 answered wrong and 17 correctly. Each question has 5 choices. We can’t learn anything about possible cheating from the questions answered correctly…the students are supposed to know those answers. However, the questions answered incorrectly can give us some insight. Since we are led to look at them because they were answered incorrectly, there are four (not five) ways that they could answer incorrectly. (If they had chosen the correct answer at random, we would not be able to know that and would not be considering the question). Since there are four possible choices, each coincidence (if by chance) would have a probability of 1/4=1/22. There is one such factor for each wrong answer that matches, so the likelihood under the “no cheating” hypothesis is 1/216, and under the “cheating” hypothesis it is 1. For a prior, we noted that most students don’t cheat, so we took only a 1/10 prior that cheating was involved. The result of the calculation is shown in the board shot below:

Problem 1: Cheating
It seems as if we have substantial evidence of cheating.
The second problem was the taxi problem. The assumption is that the taxis are numbered consecutively from 1. We saw 7 taxis, the largest number of which was 150. We know therefore that the likelihood of there being N taxis, if N<150, is zero. We do not (and according to Bayesian theory should not) build that into the prior, since the likelihood automatically takes care of it. For N≥150, the likelihood is 1/N7.
For a prior, we noted that we are more likely to be in a small city than a large one, because small cities are more numerous. We chose a prior on N of the form 1/N, but it might have been 1/N for example, which also decreases as N increases. The rest of the calculation is a routine application of our spreadsheet method, and is shown below:

Problem 2: Taxis
We noted that the posterior probability for N=151 is about 5% smaller than that for N=150. Probably half of the posterior probability is for N≤160 or so, and most of the remainder will be for N≤175. It’s a good bet, from these data, that the number of taxis in the city is between 150 and 175, approximately.
The third problem is the first part of the drug company decision problem. There are two unknown rates of cure for the two drugs, the old one (r) and the new one (s). We have to follow the practice of re-evaluating the cure rate for the old drug, even if we have lots of data on it, because we will be using a particular sample of patients and their profile may be different from the general population. This means that we’ll have to evaluate the likelihood on a 10×10 grid, with the different values of r corresponding to different rows, and the different values of s corresponding to the different columns. For simplicity we can take the prior to be the unnormalized prior with 1 in each grid location, which means that the joint probability will (except for the factor that we get from using an unnormalized prior) be equal to the likelihood, cell by cell. For the old drug the cure/no cure statistics were 25 and 25; for the new one, 30 and 20. This means that for cure rates r and s, the entry in the likelihood cell will be of the form r25(1-r)25s30(1-s)20, as shown in the diagram for one particular cell.
Once we have the likelihoods (and the joints) calculated, we add up all of them to get the marginal, and then we may divide the marginal into each joint to obtain the corresponding posteriors, cell by cell. Then adding up the posterior probability for those cells that satisfy s>r gives us the probability that the new drug is better than the old, as shown in the board shot:

Problem 3: Drugs
s>r above the stair-stepped line. We could also have just added up the likelihoods above the stair-stepped line and divided the sum by the marginal. The answer would be the same, but the amount of work would have been less.
I asked you to think about the decision problem that is the second half of this problem for Friday.
HCOL 195 11/09/09
November 11, 2009One of our students reported how his stats 141 class had discussed the following problem: 48 managers were each given a copy of a promotion resume. All the resumes were identical, except that 24 of them stated that they were for a male candidate, and 24 a female candidate. In the case of the resumes marked as for a male candidate, 21 of the 24 managers recommended promotion. In the case of the resumes marked as for a female candidate, 14 of the 24 were promoted.
His stats class analyzed this in a frequentist way, and determined that the tail area (one-sided) was 0.021 (see figure below, left-hand side). This would indicate statistically significant evidence of bias. The student wondered how we would look at this problem from a Bayesian point of view, and what results we would get

The problem solved in a frequentist way
So I looked at the problem. I knew that if there were no bias, there would be one value of the probability p for promotion, but if there were bias, then there would be two values, 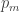



Marginal likelihood for only one common probability (no bias)
In the lower right of this picture, you will see that I remarked that the marginal likelihood we got by summing is an approximation that gets better and better, the closer we space the sample values of p. In the limit, it approaches an integral. It is in fact an integral that can be evaluated exactly by integration by parts. In general, if there were m promotion recommendations and n recommendations not to promote, the value of the integral is

where in the second form we’ve used the (m+n) choose m notation.
The calculation for two different promotion probabilities is more complex. We arrange the values for 

Two independent probabilities (bias)
We then calculate the marginal likelihood by adding all of the numbers in the joint table. Equivalently, we could add all the numbers in the likelihood table and multiply by 0.01; that gives us the same answer. At the bottom of the board, we see that the sums involving the two different probabilities are independent of each other, so we can split the sum into two independent sums over one variable, and these also are approximated by integrals (which is what we really want). That’s shown in the chart below.

Sums approximate integrals
I evaluated the required integrals using the choose(a,b) function in the free statistical computer language R, which can be obtained by googling ‘cran’. So once these are evaluated, I can compare the marginal likelihoods of the two cases. I find that the marginal likelihood for one common promotion rate is smaller than for the two independent rates case. The posterior probability of no bias is 0.21, which is ten times larger than the tail area that was calculated in the class.
However, the two calculations aren’t really doing the same thing. The calculation in the class is really computing the probability of getting data as extreme as or more extreme than what we did observe, in a direction that says there is bias against the female candidates, given that there is no bias. It’s not looking at bias in favor of females. On the other hand, our calculation assumes at the outset that there is a significant (in fact equal) prior probability of no bias as to bias, and it wouldn’t matter whether the bias was in favor of or against female candidates. We really want to investigate the probability of bias against females and for males, given that bias exists. To do that, we really want to add up only the numbers that represent bias in favor of males, and compare that to the marginal likelihood we calculated for the case of bias. This is reasonable to do, because our experience is that no one can be perfectly unbiased, so considering the case where the promotion probabilities don’t depend at all on gender is probably unreasonable. To do this, we noted that the case of bias in favor of males consists of all the numbers in the upper triangle of our array. We’ve already (in principle) computed the marginal likelihood summing over all the numbers, so we can also compute it summing only over the upper triangle. Comparing the two, we can see how much the bias in favor of male candidates is. This is equivalent to doing a double integral, where the upper limit on the inner integral depends on the value of

The calculation using integrals
Here’s the right-hand board, the illustrates the idea:

The basic idea of the calculation
I did the calculation using a completely different method. What I did was to have R draw a large number (100000) of independent samples of 
Note that there are some differences here between what we’ve done and what was done in the other class. The tail area evaluated in that class assumed that there was no bias, and calculated the probability of getting data as extreme as we did, assuming that that was true. It didn’t do any calculation that assumed that there was bias. Basically, it says that if the data are really extreme, then we are justified in rejecting the null hypothesis of no bias.
Our Bayesian calculation did the calculation assuming, in the first case, that there were two possibilities, bias or no bias, and in the second case that there was bias, and we wanted to know in what direction. And it computes the probability of the hypothesis given the data, not the other way around. It is this feature of the Bayesian way of doing things that appeals to me.
HCOl 195 11/6/09
November 6, 2009Today we discussed the ideas about money and investing found in the handout.
A new cool thing. I stumbled on this today. You will recall that we discussed the relative sizes of human cells and bacteria early in the course. I stated that bacteria are much smaller than human cells. This blog entry has a pointer to a lovely interactive page that illustrates this. By sliding the adjusting widget at the bottom, you can zoom down on smaller and smaller things.
HCOL 195 11/4/09
November 5, 2009Today we discussed “gambler’s ruin.” This is the idea that if we bet over and over small amounts, we will under some circumstances eventually go bust. I mentioned it in connection with the following scenario: Someone has borrowed money from a loan shark. The loan shark wants his money and interest back, and threatens to break the legs of the borrower if he doesn’t come up with the $200 owed tomorrow. The man has only $100, and his only plan is to go to the casino and attempt to win another $100. What should he do?
A student suggested that he should bet the whole $100 on one spin of the roulette wheel (odds of winning are 18/38 at an American casino). That was felt to have the greatest probability of success.
So we considered the idea of betting against a casino that has an infinite amount of resources. I drew a picture on the board:

Gambler's Ruin
In the diagram, we imagine that we start with $1 and bet it. The probability that we win is p=18/38, and the probability that we lose is 20/38. If we lose, we bust. If we win, we will go from $1 to $2. But we still might go bust, for example, we might lose the next two tries and end up with nothing, or we might bounce around a bit but eventually end up with nothing. If P1 is the probability that we eventually go bust, starting with $1, and P2 is the probability that we eventually go bust, starting with $2, then
P1=q+p*P2,
that is, we either bust immediately with probability q, or we obtain a second unit but eventually bust with probability P2.
But P2=P12. The reason is that if we have $2, then (since the bets don’t know how much money we have), the probability that we will eventually have a situation of having $1 is the same as the probability that we will bust if we start with $1, since it’s just the probability that eventually we will have $1 less than we have now. Therefore,
P1=q+p*P12
This is a quadratic equation for P1. There are two roots: 1 and q/p. If q>p then that root is not a possible root (since probabilities have to be no bigger than 1), and the only solution would be 1. But that means that in a real casino, where q/p>1, the only usable root is 1 and if we start with $1 and keep playing indefinitely, we will eventually bust. But that means that no matter how much money we start with, we will eventually bust, because if we start with $100, say, the probability is 1 that we will at some point have $99 ($1 less than we have now). But then the probability is 1 that we will at some point have $98, then $97, and so forth until we bust. We cannot beat the casino because the odds are in its favor.
The calculation of the roots is shown below and then on the right side of the board in the picture above.

Gambler's Ruin 2
Next, we consider the situation where the casino has a finite amount of money (or equivalently where we have m dollars and want to gamble until we get (m+n) dollars, then quit with enough money to pay off the loan shark). So, we would like to calculate the probability that if we start with m dollars, and gamble $1 at a time, that at some point in the future we will have (m+n) dollars. We can calculate this, using what we have done with the infinite casino. That’s because if Q is the probability of never getting to (m+n) dollars, that’s the same as the probability that we eventually bust without ever getting to (m+n) dollars, and (1-Q) would be the probability that we do eventually get to (m+n) dollars. But that means that
Pm=Q+(1-Q)Pm+n, since there are two ways to bust against an infinite casino, starting with m dollars: Either bust without ever getting to (m+n) dollars (that’s Q), or get to (m+n) dollars (probability 1-Q) and then go bust against the infinite casino (probability Pm+n). From what we’ve already learned, the probability of busting against an infinite casino, starting with m dollars, is rm where r is the smaller of 1 or (q/p). That yields the equations on the last chart. But for us, (q/p)>1 so that doesn’t help us to find out the probability of starting with m dollars, and gambling $1 at a time eventually getting to (m+n) dollars. But if we reverse the roles of the gambler and the casino, the probability that we will get to (m+n) dollars is the same as the probability of a casino that has n dollars busting against an infinite casino. That exchanges the roles of m and n, and of (q/p) and (p/q), and a similar formula works. That’s shown on the last chart.

Gambler's Ruin 4
If we evaluate this for just one bet, the probabililty that we win is just 18/38=0.474. If we divide our bet in two so that m=n=2, the probability of our winning is less than this, which confirms the student’s intuition that BOLD PLAY, that is, betting the maximum amount, is the best way to keep our legs from getting broken. So bet the $100 on one spin of the wheel, and hope for the best.
I remarked that this is why the lottery isn’t a good way to plan for your retirement. If you were to bet $40 a week for your entire life, your expected net worth from gambling at the end would be $80. (In class I said $40, but I checked it out; still not a good retirement plan!)
HCOL 195 11/2/09
November 2, 2009We decided to have the second test on Wednesday, November 18.
We then turned to the question of the death penalty, which although it is not allowed under Vermont state law, could conceivably be a problem for a Vermont jury which was convened in a federal capital case, as one Vermont jury recently was faced with this problem. I pointed out that a potential juror will be required to answer questions in vior dire, where each juror is questioned under oath about the case: Do you know the defendant or the victim, what have you heard about the case, can you render an impartial verdict, etc. In a capital case, you will also be asked whether you are opposed to the death penalty, and if you answer “yes,” then you will not be allowed to serve on that jury.
We then proceeded to consider a decision tree for a juror. This is a linked decision, so we need to have a second decision box if the jury decides to convict, since the second choice is “Death” or “Life in Prison.” See below for the general form of the tree, which we drew without many of the losses inserted.
We noted that each juror will have different losses for the outcomes. AI is clearly the best, with a loss of 0. It seems like we ought to assign some small loss to CG, Life, and since the scale is arbitrary, we assigned 1 for that case. We then considered what the loss should be for AG, and decided on 10 for this (although we also discussed 100; since we are illustrating the process, and everyone will come up with their own loss structure, we can use whatever will illustrate the process):

Determining loss for AG relative to CG, Life

Determining loss for CI, Death
We decided that convicting an innocent person and putting him in prison for life was pretty bad, and with a similar tree (not shown, sorry, I didn’t snap a picture of it), we settled on CI, Life=1000 for the loss. Then, we drew the above picture, and noted that CI, Death is worse (for the juror) than CI, Life. That means (if you believe it) that in the above trial decision, we should set p0 to some number less than 1, so the loss for CI, Death should be 1000/(1-p0) and will be larger than 1000. We then entered our losses, determined in this way, into the decision tree we had sketched before:

Death penalty decision tree
Because of the last observation, it’s clear that if we think that sending an innocent person to his death is worse than putting him in prison for the rest of his life, then (if we use decision theory) we will never decide on the death penalty, regardless of whether we personally approve of that penalty or are opposed to it.
