Please note: The homework for next week has been posted in the immediately preceding blog entry. It is due on Thursday.
Comments on the homework: Some groups have been having difficulty writing down the likelihood. The likelihood for observation j is 

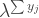
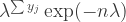
Other problem: People were programming the Gibbs sampler…They were not updating the value of the variables sent to sample1(). Need betas[i]=beta=z$beta; that middle assignment is critical. Without it, you are always sending the same position to the sampler, and it won’t move around as it should.
There was a perfect paper by undergrads in the course; the grad students need to match this!
We were talking about the linear regression model from last time, which was, you recall:

So we looked at the plots. We fit the least squares model using R function lm(), which gives the frequentist result. We looked at confidence intervals and point estimates.
For our Bayesian analysis we’ll put independent priors as per the blog last time. They were very broad priors that are almost flat. Jeff has learned that it is possible to put flat priors on the betas (but BUGS didn’t let you do that before so that’s why the priors we talked about on Tuesday are proper).
We analyzed the R code and the WinBUGS code.
Then we ran it from R (consult the R code). We looked at the output of the bugs() function in the arm package, which we called linreg.sim (see R code for this); We want Rhat close to 1 to verify good mixing. We looked at the traces, which looked good.
You can define a function and have BUGS evaluate that function over the chain and return a sample. So for example, the usual Rsquare is given by
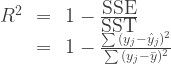
Adjusted 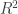
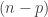
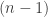
In the Bayesian case define


(closest to the adjusted
This is in the R code sent to WinBUGS.
typical.y (see the WinBUGS file) computes a posterior distribution on the estimated mean time it takes to service, using mean(cases[]), mean(distance[]).
We talked about other possibly useful features, like the log file, tracing, and the listserv.
Jeff remarked that the best way to learn BUGS is to look at the models that they have as examples.
Next example:
ANOVA models. One-way ANOVA is a useful linear model.
Our example: Interested in whether different exercise programs affect time to walking in infants.
Four different programs, called Active, Passive, No Exercise, Control Group.
Six infants in each group (randomized). Outcome is time in months when infants first walk.
Model:
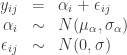
This is a random effects model and also a hierarchical model.

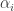
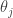 sampled conditional on the current values of all the other parameters
sampled conditional on the current values of all the other parameters  , where the dash indicates that
, where the dash indicates that  ) that is strictly positive. One way to do this is just to define the posterior conditional distribution on this parameter as zero for
) that is strictly positive. One way to do this is just to define the posterior conditional distribution on this parameter as zero for 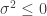 so that any attempt to propose in that region will be rejected; a simpler and probably better method is to log-transform the variable:
so that any attempt to propose in that region will be rejected; a simpler and probably better method is to log-transform the variable:  , for example. This has many advantages. One is that the Jeffreys prior on
, for example. This has many advantages. One is that the Jeffreys prior on 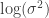 is flat.
is flat. , variance
, variance 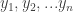 , each
, each 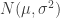 . The objective is to estimate
. The objective is to estimate  .
.![f_n(y|\mu,\sigma^2)=(2\pi\sigma^2)^{-n/2} \exp[-S_{yy}/2\sigma^2]exp[-n(\mu-\bar{y})/2\sigma^2]](https://s0.wp.com/latex.php?latex=f_n%28y%7C%5Cmu%2C%5Csigma%5E2%29%3D%282%5Cpi%5Csigma%5E2%29%5E%7B-n%2F2%7D+%5Cexp%5B-S_%7Byy%7D%2F2%5Csigma%5E2%5Dexp%5B-n%28%5Cmu-%5Cbar%7By%7D%29%2F2%5Csigma%5E2%5D&bg=ffffff&fg=333333&s=0&c=20201002) ,
,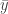 is the sample mean and
is the sample mean and  (you’ve seen this notation before).
(you’ve seen this notation before). . So the only case Jeff discussed under (1) was (1b).
. So the only case Jeff discussed under (1) was (1b). on
on  ,
,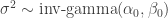
 . So Jeff only discussed (2b).
. So Jeff only discussed (2b).![g(\mu)=(2 \pi \sigma_0^2)^{-1/2}\exp[-\frac{1}{2 \sigma_0^2} (\mu-\mu_0)^2]](https://s0.wp.com/latex.php?latex=g%28%5Cmu%29%3D%282+%5Cpi+%5Csigma_0%5E2%29%5E%7B-1%2F2%7D%5Cexp%5B-%5Cfrac%7B1%7D%7B2+%5Csigma_0%5E2%7D+%28%5Cmu-%5Cmu_0%29%5E2%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![\begin{array}{rclr}g(\mu \mid \vec{y}) & \propto & f_n(\vec{y}\mid\mu)g(\mu) \\ & = & (2 \pi \sigma^2)^{n/2}\exp[-\frac{S_{yy}}{2 \sigma^2} \exp(-\frac{n}{2 \sigma^2} (\mu-\bar{y})^2-\frac{1}{2 \sigma_0^2}(\mu-\mu_0)^2] (2 \pi \sigma_0^2)^{-1/2}\end{array}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Barray%7D%7Brclr%7Dg%28%5Cmu+%5Cmid+%5Cvec%7By%7D%29+%26+%5Cpropto+%26+f_n%28%5Cvec%7By%7D%5Cmid%5Cmu%29g%28%5Cmu%29+%5C%5C+%26+%3D+%26+%282+%5Cpi+%5Csigma%5E2%29%5E%7Bn%2F2%7D%5Cexp%5B-%5Cfrac%7BS_%7Byy%7D%7D%7B2+%5Csigma%5E2%7D+%5Cexp%28-%5Cfrac%7Bn%7D%7B2+%5Csigma%5E2%7D+%28%5Cmu-%5Cbar%7By%7D%29%5E2-%5Cfrac%7B1%7D%7B2+%5Csigma_0%5E2%7D%28%5Cmu-%5Cmu_0%29%5E2%5D+%282+%5Cpi+%5Csigma_0%5E2%29%5E%7B-1%2F2%7D%5Cend%7Barray%7D+&bg=ffffff&fg=333333&s=2&c=20201002)



 and the standard deviation
and the standard deviation 
 , flat prior on
, flat prior on 
 unknown,
unknown,  is very similar to case (1a). See the notes. The result is
is very similar to case (1a). See the notes. The result is ,
,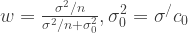
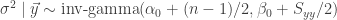
 is the number of cases stocked,
is the number of cases stocked,  is the distance in feet from the truck to the machine.
is the distance in feet from the truck to the machine.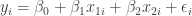 for i=1,…,25
for i=1,…,25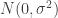 and independent (
and independent (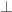 ). Let
). Let  precision.
precision. and
and  , specifically
, specifically 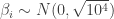 and
and  gamma(0.01,0.01)
gamma(0.01,0.01) -dimensional parameter
-dimensional parameter  , if its density
, if its density![g(\theta) \propto \exp\left[-\frac{1}{2}(\theta^T A \theta -2 b^T \theta)\right]](https://s0.wp.com/latex.php?latex=g%28%5Ctheta%29+%5Cpropto+%5Cexp%5Cleft%5B-%5Cfrac%7B1%7D%7B2%7D%28%5Ctheta%5ET+A+%5Ctheta+-2+b%5ET+%5Ctheta%29%5Cright%5D&bg=ffffff&fg=333333&s=1&c=20201002) ,
, is a
is a 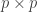 matrix and
matrix and  a
a  vector, then
vector, then
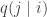 for any two states
for any two states 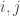 , then we satisfy the detailed balance condition by choosing
, then we satisfy the detailed balance condition by choosing  where
where
 in the state space
in the state space 
 from the arbitrary but fixed proposal distribution
from the arbitrary but fixed proposal distribution  according to the above prescription.
according to the above prescription.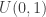 random variable
random variable  .
.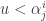 , then accept
, then accept  proportionally to
proportionally to  , so there is a point where taking more and more samples doesn’t improve things much. The standard deviation of our estimate of the posterior mean, for example, only improves by a factor of about 3 when we take 10 times as many samples, and 10 if we take 100 times as many samples. I also pointed out that taking more and more points doesn’t change things like the standard deviation of the posterior distribution; but it does improve our estimate of that standard deviation.
, so there is a point where taking more and more samples doesn’t improve things much. The standard deviation of our estimate of the posterior mean, for example, only improves by a factor of about 3 when we take 10 times as many samples, and 10 if we take 100 times as many samples. I also pointed out that taking more and more points doesn’t change things like the standard deviation of the posterior distribution; but it does improve our estimate of that standard deviation. of random variables on some state space
of random variables on some state space  , that is, each each state depends only in the immediately preceding state and is independent of all of the states before that; the Markov chain has no “memory” of exactly how it got to the last state.
, that is, each each state depends only in the immediately preceding state and is independent of all of the states before that; the Markov chain has no “memory” of exactly how it got to the last state. does not depend on the value of
does not depend on the value of  . A stationary Markov chain is characterized by a transition matrix
. A stationary Markov chain is characterized by a transition matrix  , also known as the Markov matrix. The entries of the Markov matrix satisfy
, also known as the Markov matrix. The entries of the Markov matrix satisfy  and, since every state
and, since every state  must go somewhere, probability must be conserved and
must go somewhere, probability must be conserved and  .
. over the states such that
over the states such that  for all
for all  .
. and asked to determine the stationary distribution
and asked to determine the stationary distribution  with transition matrix
with transition matrix  , then
, then  . Obviously if the equilibrium distribution is conserved for each pair of states, it will be conserved overall.
. Obviously if the equilibrium distribution is conserved for each pair of states, it will be conserved overall.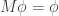 and
and 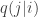 which says that if we are in state
which says that if we are in state  is the required Markov matrix.
is the required Markov matrix.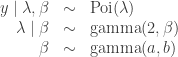
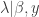

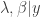 We see that
We see that
 , (see * above), we can read off that
, (see * above), we can read off that 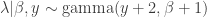
 , we see that
, we see that 
 , inverse gamma).
, inverse gamma).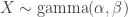 means
means
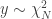 means
means 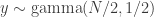
 means
means 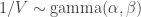
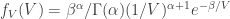 from which we get
from which we get![E[V]=\beta/(\alpha+1)](https://s0.wp.com/latex.php?latex=E%5BV%5D%3D%5Cbeta%2F%28%5Calpha%2B1%29&bg=ffffff&fg=333333&s=0&c=20201002) for
for 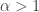 , mode is
, mode is 
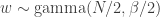 then
then 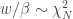
 then
then 
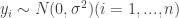 then if the prior on
then if the prior on  , we have
, we have
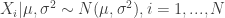 and
and 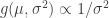 (looks like
(looks like 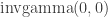 but is improper. )
but is improper. ) , where
, where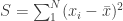

 By inspection this is inverse gamma with parameters N/2, S/2, where
By inspection this is inverse gamma with parameters N/2, S/2, where  .
.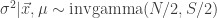
 but we did not know it when doing the marginal-conditional sampling. In the previous case the difference involves
but we did not know it when doing the marginal-conditional sampling. In the previous case the difference involves  (way off). What happens? The sampler very quickly moved to the region of interest.
(way off). What happens? The sampler very quickly moved to the region of interest.