Jeff mentioned an R package for doing Bayesian model averaging. The package can be found here, and a page with more information can be found here.
Archive for April, 2009
STAT 295, 4/28/09
April 29, 2009STAT 295, 4/23/09
April 24, 2009Bill talked about Bayesian model selection on Thursday. I mentioned that there are frequentist versions of model selection. A very readable exposition of the topic is given in the book “model selection and multimodel inference” by burnham and Anderson. The book is a classic among wildlife biologists.
I also mentioned that the text used for our 251/261 sequence, “statistical inference” by casella and berger, has a very readable account of the likelihood, sufficiency and ancillary principles and Birnbaum’s theorem. But then again, you have to consider whether you should always live by principles!
Here are links to two papers that explore the difficulties of calculating marginal likelihoods. They came from the 2006 Statistical Challenges in Modern Astronomy conference at Penn State University. Paper 1; Paper 2.
Charts for Thursday
April 22, 2009Here’s the chart set for Thursday, on Model Selection/Averaging.
Here’s the link to the great Slydini. You can watch this full-screen by clicking on the icon in the lower right of the video screen (just to the left of the volume control).
URLs mentioned on Thursday
April 17, 2009The following URLs were mentioned on Thursday:
1. Berger and Delampady paper
2. Berger and Sellke paper, with comments and rejoinder); Also here’s a paper on the subject from American Statistician.
Both these papers come with a discussion by several statisticians and a rejoinder by the authors.
3. Jim Berger’s web page with comments about p-values and Java applet to simulate the experiment discussed in class.
Note that the papers by Berger and Delampady and by Berger and Sellke must be accessed from within the university network or by proxy server.
“On Bayesian Model and Variable Selection Using MCMC,” by Petros Dellaportas, Jonathan Forster and Ioannis Ntzoufras
Stat 295, April 16, 2009
April 17, 2009The lecture today continued on the topic of hypothesis testing, and Bill discussed some issues with frequentist hypothesis testing. There is some disagreement among analysts concerning how hypothesis testing should be carried out and also some confusion concerning interpretation of p-values. The issue is complex (else there wouldn’t be so much disagreement).
First, in most applications it is better to compute and report confidence/credible intervals, and avoid hypothesis testing altogether. In other applications, you need to decide whether it makes sense to construct a decision rule, or alternatively whether it makes sense to simply present the evidence against the null for the observed data. If the constructing a decision rule makes sense, then choose an alpha level, construct a rejection region and reject when the test statistic falls in the rejection region. Quality control applications often appropriately use this methodology–stop the process if it is ‘out of control’.
On the other hand, if you don’t want to make a decision between an alternative and a null, but simply want to quantify the evidence in the data against a null hypothesis (the alternative doesn’t even come into play), then compute a p-value. P-values are clearly defined to present evidence against the null. But don’t confuse p-values with type-I error rates.
Regarding interpretation of p-values, page 30 of the notes says
Then amongst those experiments rejected with p-values in
for small epsilon, at least 30% will actually turn out to be true, and the true proportion can be much higher (depends upon the distribution of the actual parameter for the experiments where the null is false)
This says that under these circumstances, the Type I error rate (probability of rejecting a true null), conditioned on our having observed p=0.05, is at least 30%!
I think one needs to think carefully about this claim. The type I error rate is the probability of rejecting a null given the null is true. The 30% referred to above is not a type I error rate because it considers p-values computed under alternatives, so I don’t think it is fair to compare the 30% to a type I error rate. They are not measuring the same quantity. Is it surprising that a large proportion of p-values in the indicated range would come from the null? I don’t think so, especially if the alternatives tend to be quite far from the null.
Summer School on Spatial Statistics
April 15, 2009SAMSI (the Statistical and Applied Mathematical Sciences Institute), in Research Triangle Park, North Carolina, is sponsoring a Summer School on Spatial Statistics, running from July 28-August 1, 2009. Financial aid is available. The target audience is advanced undergraduates and graduate students, and a first course on Bayesian statistics as well as the usual background in regression, etc., is desirable. Anyone who has finished this class ought to be eligible. Application is through the web site; if you are interested, apply early as they will be accepting applications as they come in and enrollment is limited.
From Andrew Gelman’s blog
April 15, 2009Andrew Gelman posted some amusing graphs on his blog. Take a look here.
Chart Set 11: Bayesian Hypothesis Testing
April 10, 2009Here is the eleventh chart set, on Bayesian hypothesis testing.
Homework, Due 4/16/09
April 10, 2009Here is a link to an html page for the next homework problem (#10). There is a paper to download which will give you some background for the problem.
Stat 295, 4/9/09
April 9, 2009We left off last time with model for heart transplant mortality data over 94 hospitals.

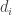

Want to estimate all the 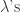
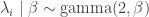

The BUGS code and data were already posted, but Jeff has modified the code here. We ran the code and plotted the MLEs against the posterior means. We saw that they would be identical if they fell along the line x=y. We saw shrinkage. We noted that even though some hospitals had zero deaths, their shrunken estimators were pulled towards 1. The same thing happened for hospitals where 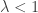
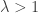

For hospital 9, although 1 is included in the credible interval, we can calculate the probability that its death rate is high by computing (in R): mean(lambda[,9]>1)=0.84, so the probability that it is 
A similar calculation (with between difference) can compute probability that hospital i is better than the best hospital (say #1): 
Mike asked: What is “significant”? Answer, it’s not really appropriate to think of this in terms of “statistical significance”, which is a frequentist notion. A Bayesian would more likely ask, what’s the decision-theoretic way to look at this? An insurance company and a hospital director might have different loss functions and therefore might take different actions upon learning this information.
In hierarchical models, we have to be careful about using improper priors. This is because you can get improper posteriors.
Classic example:
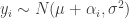

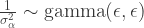
As 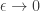
There’s a discussion of this in Gull’s paper “Why I Am A Bayesian.” Look up “sermon on the spike” near the end.
Priors: Choosing a prior, or having to choose a prior, is perhaps the bane of being Bayesian. Or maybe the advantage of being Bayesian. (Uninformative might be the bane, said Jeff).
We can organize the discussion into three main themes: Informative, Noninformative, Conjugate.
1. Informative:
a) You have prior data and can use this to determine a prior. This might come from previous studies, e.g., if you analyze hospitals year to year.
b) Subjective or elicited priors.
2. “Noninformative”: (the holy grail, always out of reach).
a) Mathematical principles for choosing noninformative priors.
i) Jeffreys’ rule
ii) Maximum entropy
iii) Invariance
b) Reference priors: the idea is to find a prior that is “automatic” for a given model and convenient to use as a standard for a particular model.
3. Conjugate priors:
Mathematical convenience is the raison d’etre. The prior and posterior are in the same family. It seems that most if not all conjugate prior examples are in the exponential family of distributions.
We talked about noninformative priors. Jeff motivated the discussion with an example showing the difficulties.
Example:
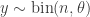

Suppose another analyst uses a different parameterization: Instead of using 
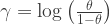
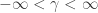


The prior in terms of 
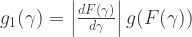
where the derivative is 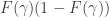
The result is a bell-shaped curve with most of the mass between -4 and 4. In particular, it is not flat. The prior is no longer uniform.
The dilemma can be described as follows:
1. Two analysts, using the same probability model for the data but different parameterizations, and each using a uniform prior under their parameterization, will arrive at different posterior inferences. Thus, you can’t say “always use a uniform prior.”
2. On the other hand if we start with a uniform and go over the the other prior on transformation, the inferences will be the same. 

2a)1) Jeffreys’ Rule. Harold Jeffreys gave a rule that specifies how to determine a prior after the probability model for the data, 
Jeffreys’ Rule:
We’ll consider the 1-dimensional case. Let
![I(\theta)=E\left[\left(\frac{d \log f(y\mid\theta)}{d\theta}\right)^2\right] = -E\left[\frac{d^2 \log f(y\mid\theta)}{d \theta^2}\right]](https://s0.wp.com/latex.php?latex=I%28%5Ctheta%29%3DE%5Cleft%5B%5Cleft%28%5Cfrac%7Bd+%5Clog+f%28y%5Cmid%5Ctheta%29%7D%7Bd%5Ctheta%7D%5Cright%29%5E2%5Cright%5D+%3D+-E%5Cleft%5B%5Cfrac%7Bd%5E2+%5Clog+f%28y%5Cmid%5Ctheta%29%7D%7Bd+%5Ctheta%5E2%7D%5Cright%5D&bg=ffffff&fg=333333&s=1&c=20201002)
Jeffreys’ rule says to choose the prior density 

In the binomial case
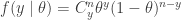
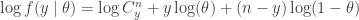
But since ![E[y]=n\theta](https://s0.wp.com/latex.php?latex=E%5By%5D%3Dn%5Ctheta&bg=ffffff&fg=333333&s=0&c=20201002)


Note:

