The next chart set is on Model Selection and Model Averaging.
The chart set about missing data can be found here.
We started by discussing how our prior belief in a hypothesis can affect our approach to the data, e.g., guessing three cards right if the subject is a child who looks at the face of the cards, or a magician who looks only at the backs of the cards, is a priori more believable than that the subject is a real psychic. We looked at the Soal-Bateman example, where it was eventually shown that the amazing results were due to cheating. I discussed a general framework whereby very unlikely data can raise a more plausible hypothesis (cheating) over a less plausible one (psychic powers are real) when we take care to include all possible hypotheses in the analysis. A student asked, how can we do this? In fact we can never consider all possible hypotheses, there are just too many of them. The best we can do is to consider all hypotheses that might be plausible enough to have their posterior probabilities raised to significance. I finished this chart set by pointing out that just doing hypothesis tests isn’t really how decisions should be made. Really we should be using decision theory, and it turns out that essentially all admissible decision rules in classical (frequentist) decision theory are Bayes rules. Decision theory looks not only at the probabilities, but also at the costs of the decisions we make.
We then turned to model selection and model averaging. Model selection is an obvious extension of the hypothesis testing situation, except that instead of having just two models we have multiple models. The trickiest part of model selection (and averaging) is assigning priors on the parameters of the different models since if they are too vague, they will artificially favor models with fewer parameters. Unlike likelihood ratio tests, the Bayesian model selection idea can be used on non-nested models.
I also discussed approximate methods for model selection, the AIC (Akaike Information Criterion) and Schwartz’ BIC (Bayesian Information Criterion, which is not particularly Bayesian since it ignores the priors on the model parameters). BIC penalizes larger models more than AIC. Closer looks at BIC show that it reduces to the usual asymptotic form for hypothesis testing of a simple vs. a complex hypothesis.
I demonstrated the Zellner g-prior idea for linear models.
Model averaging is related but different. In model selection we average (marginalize) with respect to all the parameters and look at the posterior probabilities of the models. In model averaging there is a parameter that is common to all models that we are interested in, and we marginalize with respect to all the other model parameters and with respect to the models, so that all models contribute to the estimate of the parameter that we are interested in, in proportion to the posterior probabilities of the models themselves.
Finally, we looked at normal linear models. We saw that the prior on 
We finished by looking at Gull’s approximation and a polynomial example that he presented. I noted that in his Figure 8, the y-axis is the log of the posterior probability, so it actually decreases much more rapidly after the peak is reached at N=10 than the figure seems to indicate.
 , so the larger the data set (for a given p-value), the more strongly the null hypothesis will be supported. Jack Good suggested a way to convert p-values to Bayes factors and posterior probabilities that, as we calculated, does a pretty good job (but it is approximate).
, so the larger the data set (for a given p-value), the more strongly the null hypothesis will be supported. Jack Good suggested a way to convert p-values to Bayes factors and posterior probabilities that, as we calculated, does a pretty good job (but it is approximate). which requires a prior. Then to consider just the two hypotheses we have to marginalize the posterior probability on the complex hypothesis with respect to
which requires a prior. Then to consider just the two hypotheses we have to marginalize the posterior probability on the complex hypothesis with respect to  by including a factor of
by including a factor of  in the likelihood; and second, using a hierarchical independence Jeffreys prior on
in the likelihood; and second, using a hierarchical independence Jeffreys prior on 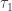 and
and  .
.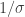 prior. We then looked at unknown mean and unknown variance and (with apologies) we finally ground through to get
prior. We then looked at unknown mean and unknown variance and (with apologies) we finally ground through to get 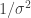 . Jeffreys didn’t like this (it is what you get for the left invariant Haar prior, which Jim Berger thinks we should not be using). Instead he favored the “independence Jeffreys prior”, which is flat x
. Jeffreys didn’t like this (it is what you get for the left invariant Haar prior, which Jim Berger thinks we should not be using). Instead he favored the “independence Jeffreys prior”, which is flat x 